Introducing Self-Driving Production: Traversal's Vision for Software That Runs Itself

Autonomous software development is evolving fast. OpenAI's Harness Engineering built entire products with zero manually-written code. Cursor's Long-Running Agents demonstrated 52-hour autonomous coding sessions. They share a common architecture: an engineer identifies a problem, writes a specification, and hands it to an agent. The agent iteratively builds in a contained environment. Things look good, and this code is then shipped over to production.
Then something breaks. But this is where the hardest work actually begins — and it's still entirely on the engineers. Before the agent can act, an engineer has to open dashboards, sift through telemetry data, identify what's broken, diagnose why, and translate that into a specification. After the agent ships a fix, an engineer has to verify it actually solved the problem — back in the same dashboards, checking the same telemetry. The agent can write code, but it has no visibility into production. It depends entirely on engineers at both ends.
This is open-loop autonomous development. But what happens when you close the loop entirely?
At Traversal, we've built an AI SRE that is able to reason over telemetry data at petabyte scale — autonomously troubleshooting, remediating, and preventing production incidents for companies like Pepsi, American Express, Digital Ocean, and Cloudways. Recently, our engineers closed the loop entirely: we run Traversal on Traversal, and it now monitors its own production environment, finds bugs, writes the fix, deploys it, and verifies it worked.
We're calling it self-driving production. Book a demo to see how you can also close the loop with Traversal.
Why Closing the Loop is Hard
Writing code and running code in production are fundamentally different problems. Development is largely static: you write locally, test locally, and the environment is controlled. AI coding agents now excel at writing code because the feedback loop is self-contained. But they only see how the code performs in this contained environment.
Code, however, only comes alive once it hits production at scale. That’s when you have various parts of an enterprise system interacting in ways that you simply cannot test for when developing code — and the only way to understand how it's performing live is through telemetry data. The problem is that this data is scattered across dozens of tools; your system's complex interdependencies are constantly shifting; and the knowledge that actually mitigates incidents still lives in your engineers' heads. AI agents can bring the speed and coverage needed to reason about production, but today's telemetry was built for humans browsing dashboards, not agents running a massive number of parallel investigations over petabytes of data; further, most observability tools can only tell you what moved together, not what caused what. Doing this at enterprise scale, across thousands of services, in minutes rather than hours, remains the hardest unsolved problem in running software at scale (learn more from our article on Why You Can't Build an AI SRE with Claude Code).
That's why closing the loop isn't a coding problem. It requires a fundamentally different AI agent architecture: one that can monitor production, detect what's gone wrong, and perform deep root cause analysis to identify actionable fixes. Only once accurate mitigation steps have been identified can the coding agent handle what comes next — writing and shipping the fix. Without an agent that can reason about production data at scale, the loop stays open.
Closing the Open Loop
Traversal's AI SRE was built to solve exactly this — and everything that follows isn't theoretical. It runs on our own production environment, monitoring our telemetry, detecting anomalies, diagnosing incidents, and fixing issues, all autonomously.
When an experienced engineer troubleshoots an incident, they don't just look at what spiked at the same time. They reason causally: what depends on what, what changed recently, what's upstream of the failure, what's a symptom versus the cause. That reasoning is what actually mitigates incidents. Any system that closes the loop needs to solve two problems: first, making your entire production environment — its topology, baselines, code, dependencies, and tribal knowledge — legible to AI at scale. And second, reasoning over that environment causally, not just correlationally, at the speed of AI - compressing hours of human investigation into minutes.
Under the hood, those are exactly the two problems Traversal has spent years solving, resulting in two foundational capabilities driven by AI breakthroughs: the Production World Model™ and the Causal Search Engine™.
- The Production World Model™ takes the fragmented, sprawling telemetry described above and compresses it into a structured, machine-readable representation of how production actually behaves: live dependencies, behavioral baselines, change history, error propagation paths, and encoded tribal knowledge via Knowledge Bank™. Not a static diagram or a stale runbook, but a continuously learning, living model.
- When something breaks, the Causal Search Engine™ investigates over the Production World Model™. Traversal goes far beyond correlating alerts: an agent runs thousands of parallel queries and reasons causally to determine exactly what broke, why, and where in your system it started, presenting you with the root cause.
Engineers already reason this way — but not across thousands of services in minutes. Correlation-based tools can move at that speed, but they have high false positive rates. The Causal Search Engine™, searching over the Production World Model™, delivers both. That is what’s required to close the loop.
What a Closed-Loop System Looks Like
That's the architecture. Here's what it looks like running a self-driving production system end to end.
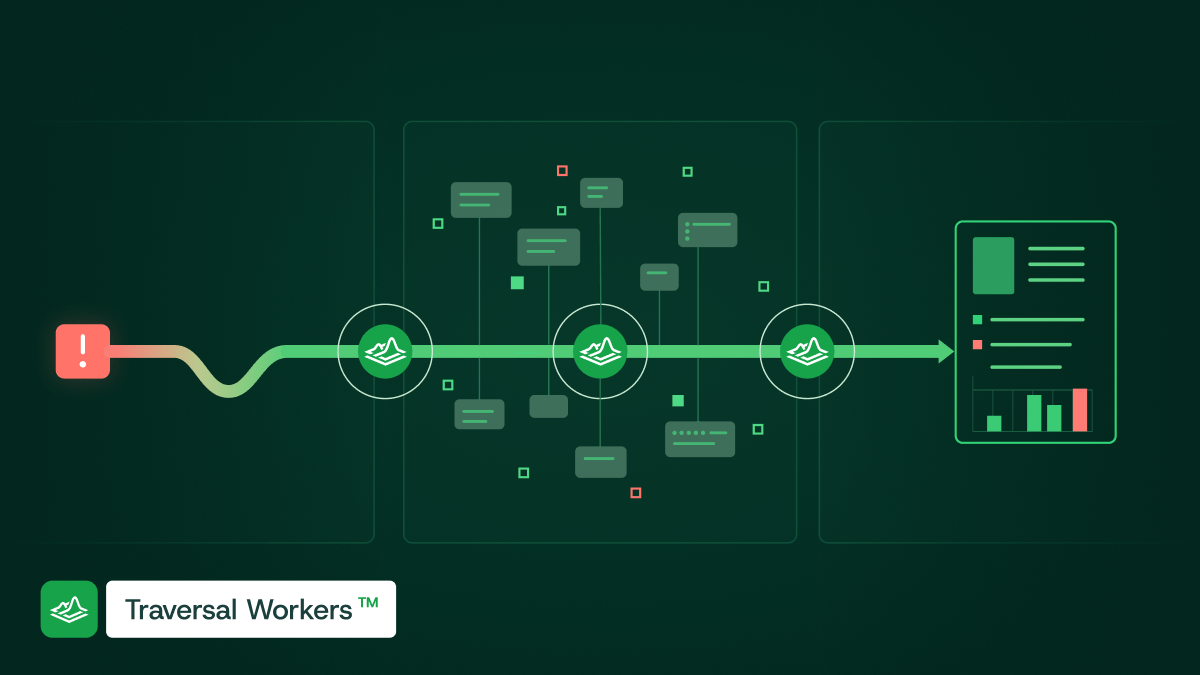
We recently shipped an autonomous ticket controller that connects the output of our AI SRE directly to our development workflow. The specific tools are interchangeable, but the architecture is the same:
- Traversal detects an issue in its own production environment: an error spike, a degraded endpoint, a flaky integration. This is powered by Alert Intelligence, a long-running agent that continuously watches every alert in the environment.
- Traversal runs a full root cause analysis, powered by the Causal Search Engine™ searching over the Production World Model™, to determine exactly what went wrong, why it propagated, and where in the codebase the problem originates. Not every issue results in a ticket. Traversal only creates one when the RCA identifies a specific, actionable fix to implement.
- A coding agent spins up with the full diagnostic context from the RCA: the failing service, the dependency chain, the relevant logs, the exact error path, and the change context that triggered the regression. It implements the fix, runs the test suite, and creates a PR for engineer review. The fix is then deployed.
- Traversal monitors its own production environment. If the fix restores the system to its expected behavioral baselines, the loop is complete. If it introduces a new issue, the cycle starts again.

This is a closed-loop system. The same AI that detects the problem also fixes it.
There’s no handoff between a “coding system” and a “detection system”: it’s one recursive system reasoning over a living model of production. This is self-driving production.
The Autonomy Curve for Production
The industry has made enormous progress on the coding side. The production side is where the curve gets interesting.
Closing that gap isn't binary, it's a progression. The self-driving car industry defined this years ago: six levels of autonomy, from L0 to L5, fully manual to fully autonomous, each one removing a human dependency.
Below we provide an analogous framework, which enterprises can use to map how close they are to fully self-driving production:
- At L0, it's all manual. War rooms, dashboards, 50 engineers in a Slack channel at 3AM. This is still the reality for most enterprises' hardest incidents.
- L1 automates the known problems using pre-defined rules and classical machine learning. Brittle thresholds trigger alerts, pre-defined runbooks handle familiar failure modes. But the moment something novel happens, the system stalls or creates far too many false positives, and an engineer takes over.
- L2 adds LLMs to the mix, but only as an assistant. LLMs condense logs, draft postmortems, and translate what an engineer is already looking for into specific structured queries. Useful for reducing noise and speeding up investigation, but the engineer is still in the driver's seat.
- L3 is where AI agents start investigating, but only within a single domain: Kubernetes troubleshooting, log analysis within one observability platform, cloud infrastructure diagnostics. Helpful in their lane, but these systems aren't truly agentic; they work where playbooks are well-established and the problem space is narrow. But incidents that cross boundaries are where the major pain points are. This is where most of the industry stalls.
L0 through L3 are copilots, or AI that assists an engineer who's still driving. Most AI SRE companies today sit at L2, with some reaching L3 — though often only through heavy forward-deployed engineering that doesn't scale. The jump to autopilot requires a fundamentally different architecture: a live model of your entire production environment (Production World Model™), the ability to reason over it causally and at scale (Causal Search Engine™), and encoded operational knowledge from your team (Knowledge Bank™). Without that foundation, you can build a better copilot, but you fundamentally can't build an autopilot.
- L4 is where the autopilot begins: autonomous causal investigation across your full production environment — every service, every dependency, every infrastructure layer. Humans still control critical decisions, but the investigation no longer depends on them. This is where Traversal operates today.
- L5 is the destination: self-driving production. Here, the system has internalized your environment deeply enough to act on its own: not just detecting and diagnosing, but remediating issues as they arise and preventing them before they surface. The system doesn't page you at 4AM with a diagnosis. It fixes the problem, verifies the fix, and briefs the engineer in the morning. Engineers stop firefighting and go back to building.
The leap from L4 to L5 isn't just technical; it's also about trust. Once an AI SRE has demonstrated high enough accuracy in detection, root cause analysis, and actionable mitigation, the question is whether an enterprise is ready to hand over the keys to an AI Agent to do the fix. That's why accuracy is our obsession at L4: it's what earns the right to operate at L5. Internally, we're already there — Traversal runs at L5 on its own production environment today.
We are uniquely positioned to become the backbone of autonomous software development in production. Not because Traversal is better at writing code, but because we spent years building the foundations that no one else has: the infrastructure to make production environments legible to AI, and to ensure that reasoning is accurate at petabyte scale. That’s why Traversal is the only AI SRE platform operating at L4 — continuously learning, continuously strengthening, and compounding with every investigation — and why L5 is a matter of when, not if.
The Road to Self-Driving Production
The autonomous ticket controller is running in production today, handling real tickets on our codebase. Engineers still review every PR. The system still escalates when it gets stuck. But the trajectory is clear: as AI gets better at writing code, and our AI SRE gets better at diagnosing production issues, engineers spend less time firefighting and more time on the work that actually moves the business forward — architecting systems, designing features, and making strategic decisions.
We don’t see this as a distant thought experiment or just another blog post. This is our vision for the future of production systems — and what we're building toward at Traversal.
Book a demo to see how you can close the loop autonomously with Traversal.
ABOUT TRAVERSAL
Traversal is the frontier lab behind the first and only AI SRE platform validated within the Fortune 100. Backed by Sequoia and Kleiner Perkins, we help enterprises autonomously prevent, diagnose, and heal production incidents at scale. If you're interested in autonomous incident resolution, get in touch.

.png)


.png)